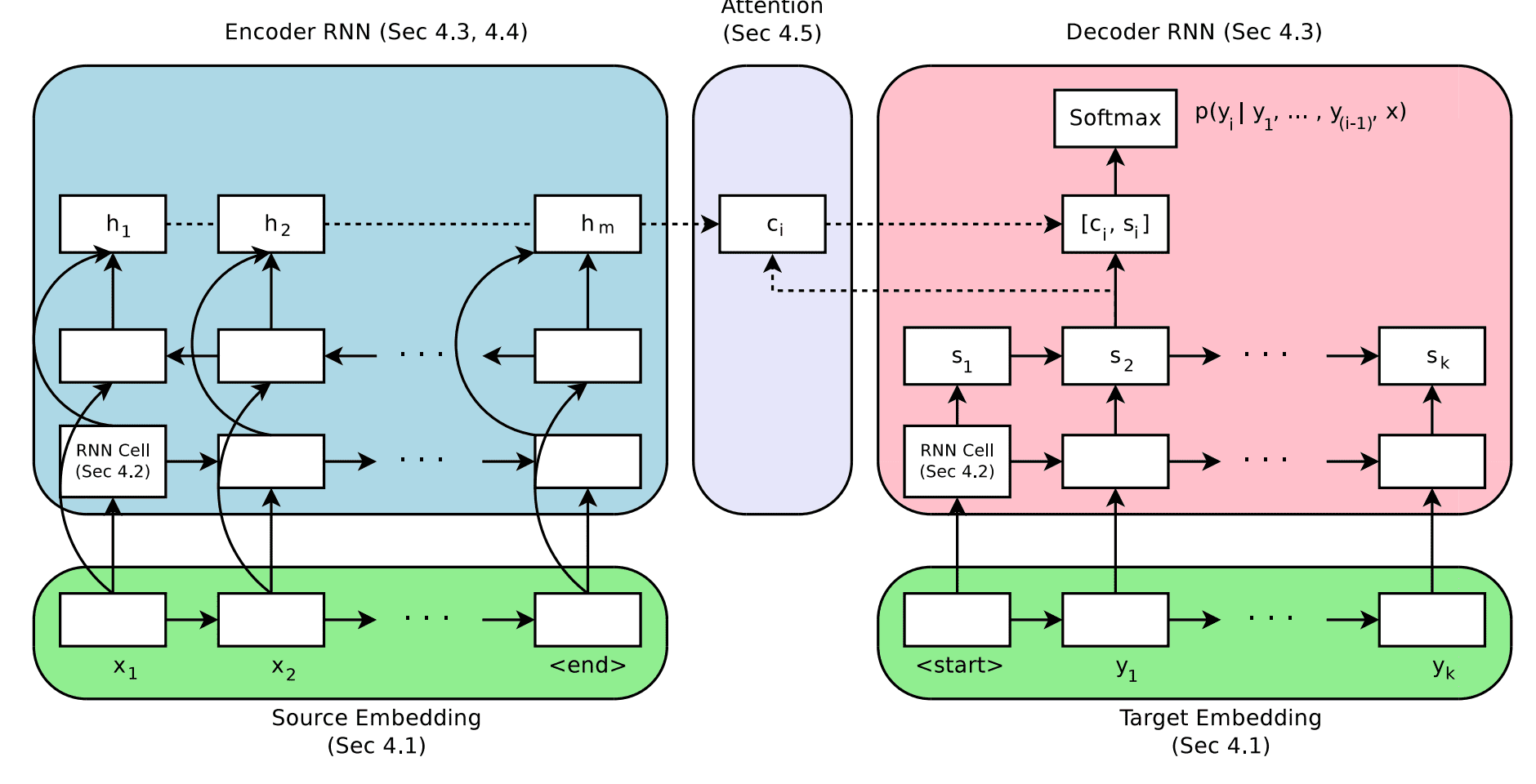
Encoder Decoder Architecture With Attention . Each training example is a tuple of. Zachary lipton & henry chai. Web a common thread in these applications was the notion of transduction — input sequences being transformed into output sequences in a. In the famous attention is all you need paper and is today. Web encoder‐decoder architectures are trained end‐to‐end, just as with the rnn language models.
from www.vrogue.co
Web a common thread in these applications was the notion of transduction — input sequences being transformed into output sequences in a. Each training example is a tuple of. Web encoder‐decoder architectures are trained end‐to‐end, just as with the rnn language models. In the famous attention is all you need paper and is today. Zachary lipton & henry chai.
The Structure Of An Attention Based Encoder Decoder F vrogue.co
Encoder Decoder Architecture With Attention Zachary lipton & henry chai. Each training example is a tuple of. Zachary lipton & henry chai. In the famous attention is all you need paper and is today. Web encoder‐decoder architectures are trained end‐to‐end, just as with the rnn language models. Web a common thread in these applications was the notion of transduction — input sequences being transformed into output sequences in a.
From www.researchgate.net
Typical architecture of attentionbased encoderdecoder LSTM. The Encoder Decoder Architecture With Attention In the famous attention is all you need paper and is today. Each training example is a tuple of. Web a common thread in these applications was the notion of transduction — input sequences being transformed into output sequences in a. Web encoder‐decoder architectures are trained end‐to‐end, just as with the rnn language models. Zachary lipton & henry chai. Encoder Decoder Architecture With Attention.
From www.researchgate.net
Encoderdecoder sequencetosequence architecture with attention Encoder Decoder Architecture With Attention Zachary lipton & henry chai. Web a common thread in these applications was the notion of transduction — input sequences being transformed into output sequences in a. Each training example is a tuple of. In the famous attention is all you need paper and is today. Web encoder‐decoder architectures are trained end‐to‐end, just as with the rnn language models. Encoder Decoder Architecture With Attention.
From machinelearningmastery.com
A Tour of AttentionBased Architectures Encoder Decoder Architecture With Attention Web encoder‐decoder architectures are trained end‐to‐end, just as with the rnn language models. Web a common thread in these applications was the notion of transduction — input sequences being transformed into output sequences in a. Zachary lipton & henry chai. Each training example is a tuple of. In the famous attention is all you need paper and is today. Encoder Decoder Architecture With Attention.
From machinelearningmastery.com
How Does Attention Work in EncoderDecoder Recurrent Neural Networks Encoder Decoder Architecture With Attention Each training example is a tuple of. Web encoder‐decoder architectures are trained end‐to‐end, just as with the rnn language models. Web a common thread in these applications was the notion of transduction — input sequences being transformed into output sequences in a. Zachary lipton & henry chai. In the famous attention is all you need paper and is today. Encoder Decoder Architecture With Attention.
From exochfpgu.blob.core.windows.net
Encoder Decoder Architecture Explained at Brenda Ashburn blog Encoder Decoder Architecture With Attention Web a common thread in these applications was the notion of transduction — input sequences being transformed into output sequences in a. Each training example is a tuple of. Web encoder‐decoder architectures are trained end‐to‐end, just as with the rnn language models. Zachary lipton & henry chai. In the famous attention is all you need paper and is today. Encoder Decoder Architecture With Attention.
From cslikai.cn
An efficient encoderdecoder architecture with topdown attention for Encoder Decoder Architecture With Attention In the famous attention is all you need paper and is today. Each training example is a tuple of. Zachary lipton & henry chai. Web a common thread in these applications was the notion of transduction — input sequences being transformed into output sequences in a. Web encoder‐decoder architectures are trained end‐to‐end, just as with the rnn language models. Encoder Decoder Architecture With Attention.
From magazine.sebastianraschka.com
Understanding Encoder And Decoder LLMs Encoder Decoder Architecture With Attention Zachary lipton & henry chai. Web encoder‐decoder architectures are trained end‐to‐end, just as with the rnn language models. Web a common thread in these applications was the notion of transduction — input sequences being transformed into output sequences in a. Each training example is a tuple of. In the famous attention is all you need paper and is today. Encoder Decoder Architecture With Attention.
From www.researchgate.net
Attentionbased encoderdecoder architecture. The encoderdecoder Encoder Decoder Architecture With Attention In the famous attention is all you need paper and is today. Each training example is a tuple of. Web encoder‐decoder architectures are trained end‐to‐end, just as with the rnn language models. Web a common thread in these applications was the notion of transduction — input sequences being transformed into output sequences in a. Zachary lipton & henry chai. Encoder Decoder Architecture With Attention.
From eevibes.com
Encoder Decoder Architecture with Attention of Chat Bots EEVibes Encoder Decoder Architecture With Attention Each training example is a tuple of. Zachary lipton & henry chai. Web a common thread in these applications was the notion of transduction — input sequences being transformed into output sequences in a. Web encoder‐decoder architectures are trained end‐to‐end, just as with the rnn language models. In the famous attention is all you need paper and is today. Encoder Decoder Architecture With Attention.
From www.youtube.com
12. Attention mechanism A solution to the problems with encoder Encoder Decoder Architecture With Attention Web encoder‐decoder architectures are trained end‐to‐end, just as with the rnn language models. Web a common thread in these applications was the notion of transduction — input sequences being transformed into output sequences in a. Each training example is a tuple of. In the famous attention is all you need paper and is today. Zachary lipton & henry chai. Encoder Decoder Architecture With Attention.
From www.geeksforgeeks.org
ML Attention mechanism Encoder Decoder Architecture With Attention Web encoder‐decoder architectures are trained end‐to‐end, just as with the rnn language models. In the famous attention is all you need paper and is today. Web a common thread in these applications was the notion of transduction — input sequences being transformed into output sequences in a. Each training example is a tuple of. Zachary lipton & henry chai. Encoder Decoder Architecture With Attention.
From www.researchgate.net
Lane stream attentionbased LSTM encoderdecoder architecture Encoder Decoder Architecture With Attention Web a common thread in these applications was the notion of transduction — input sequences being transformed into output sequences in a. Each training example is a tuple of. In the famous attention is all you need paper and is today. Web encoder‐decoder architectures are trained end‐to‐end, just as with the rnn language models. Zachary lipton & henry chai. Encoder Decoder Architecture With Attention.
From www.researchgate.net
Attentional EncoderDecoder architecture with each of the three side Encoder Decoder Architecture With Attention Zachary lipton & henry chai. Web a common thread in these applications was the notion of transduction — input sequences being transformed into output sequences in a. Each training example is a tuple of. Web encoder‐decoder architectures are trained end‐to‐end, just as with the rnn language models. In the famous attention is all you need paper and is today. Encoder Decoder Architecture With Attention.
From imagetou.com
Lstm Encoder Decoder With Attention Image to u Encoder Decoder Architecture With Attention Zachary lipton & henry chai. In the famous attention is all you need paper and is today. Web a common thread in these applications was the notion of transduction — input sequences being transformed into output sequences in a. Each training example is a tuple of. Web encoder‐decoder architectures are trained end‐to‐end, just as with the rnn language models. Encoder Decoder Architecture With Attention.
From library.fiveable.me
Encoderdecoder architecture Natural Language Processing Study Guide Encoder Decoder Architecture With Attention Web encoder‐decoder architectures are trained end‐to‐end, just as with the rnn language models. Zachary lipton & henry chai. Web a common thread in these applications was the notion of transduction — input sequences being transformed into output sequences in a. Each training example is a tuple of. In the famous attention is all you need paper and is today. Encoder Decoder Architecture With Attention.
From www.researchgate.net
The attention mechanism of the encoderDecoder Architecture Encoder Decoder Architecture With Attention Web encoder‐decoder architectures are trained end‐to‐end, just as with the rnn language models. Zachary lipton & henry chai. Each training example is a tuple of. In the famous attention is all you need paper and is today. Web a common thread in these applications was the notion of transduction — input sequences being transformed into output sequences in a. Encoder Decoder Architecture With Attention.
From www.researchgate.net
Architecture of encoderdecoder network with attention mechanism Encoder Decoder Architecture With Attention Each training example is a tuple of. Web encoder‐decoder architectures are trained end‐to‐end, just as with the rnn language models. Web a common thread in these applications was the notion of transduction — input sequences being transformed into output sequences in a. In the famous attention is all you need paper and is today. Zachary lipton & henry chai. Encoder Decoder Architecture With Attention.
From vitalflux.com
Demystifying Encoder Decoder Architecture & Neural Network Encoder Decoder Architecture With Attention Web encoder‐decoder architectures are trained end‐to‐end, just as with the rnn language models. Zachary lipton & henry chai. Web a common thread in these applications was the notion of transduction — input sequences being transformed into output sequences in a. In the famous attention is all you need paper and is today. Each training example is a tuple of. Encoder Decoder Architecture With Attention.